Direct I/O for Cassandra Compaction: Cutting p99 Read Latency by 5x
A patch I contributed to Apache Cassandra 6 cuts p99 read latency by 5x during compaction.
Compaction pollutes the page cache with data the application knows is throwaway, but the kernel does not. Compaction is unavoidable, the price Cassandra pays for fast writes. Data isn't sorted on the way in; it's sorted later, in the background, by merging files on disk.
Reducing compaction throughput or increasing node memory can dampen the effect on tail query latencies. The first costs throughput, the second costs money. Both are compromises.
Direct I/O allows Cassandra to live in better harmony with its own housekeeper, bypassing the page cache entirely for compaction reads.
Linux Page Cache
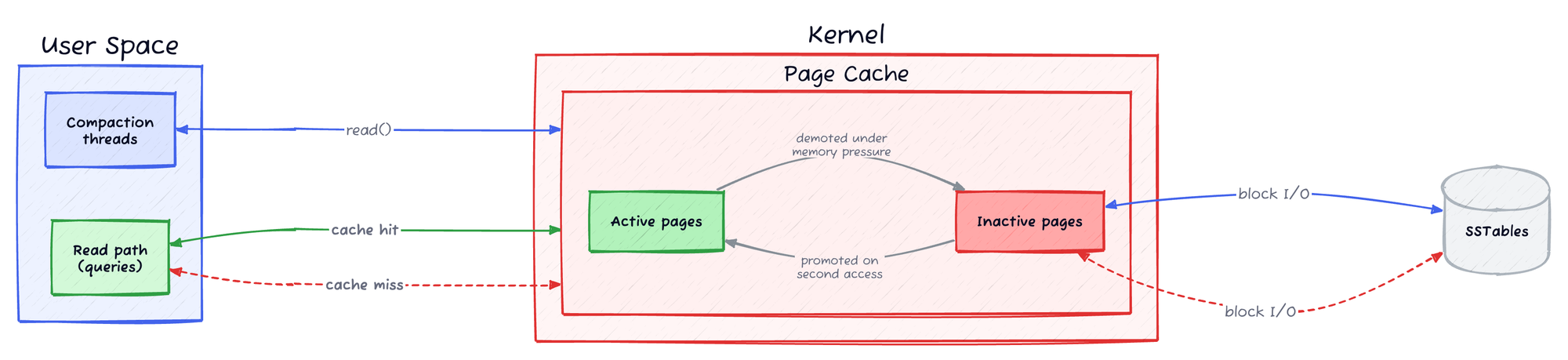
Any time a file-based read or write occurs (typically via read() and write() system calls), data passes through the page cache, a kernel-managed in-memory cache between the application and storage device.
The kernel manages this through two LRU (least-recently-used) lists: an active list and an inactive list. Hot pages live on the active list; cold or read-once pages remain on the inactive list as first candidates for eviction.
Buffered I/O works well for most applications, benefiting reads through caching and readahead, and writes through deferred, coalesced flushes, freeing the developer from reasoning about I/O sizing and access patterns.
For most workloads, the kernel makes good decisions. Not all workloads are most workloads.
Compaction and the Page Cache
Compaction, which merges multiple SSTables into a single SSTable, is a prime example of a page cache pollutant. Input SSTables are read sequentially and discarded; the output SSTable is written in a single sequential pass. Both reads and writes flood the page cache with data unlikely to be accessed again, displacing legitimate hot-page candidates.
Displacement alone would be costly. The cost of eviction makes it worse.
Clean, read-once pages from the input SSTables can be dropped immediately. Dirty pages of the newly written SSTable must first be flushed to disk before eviction is possible. Buffered writes of single-use pages are more expensive than buffered reads, and the reclaimer pays that expense.
kswapd, the kernel's background memory reclaimer, scans the LRU lists and evicts pages to keep utilisation within configured watermarks. Pages on the inactive list survive only if accessed between scans; repeated accesses earn promotion to the protected active list.
Under memory pressure kswapd cycles faster, shrinking the promotion window. When allocations outpace reclamation, free memory falls below the min watermark and the kernel stalls the allocating thread. This is direct reclaim: the thread must free pages from memory itself before its allocation can proceed, blocking the triggering operation.
For the compaction thread, a tolerable delay. For a critical read query that triggers a cache miss and must load pages from disk, it is not.
Inflated tail latencies are inevitable. The kernel and Cassandra each have mitigations. Neither is enough.
Existing Mitigations
The kernel's active/inactive page cache split provides some hot page protection. Read-once pages are contained in the inactive list. Premature eviction of hot page candidates remains the problem.
Cassandra uses FADV_DONTNEED to hint to the kernel that compaction pages can be dropped, but only once an SSTable is fully processed. The pollution occurs during processing; the hint arrives too late.
FADV_DONTNEED was adopted in 2010 in this Jira after both fadvise and Direct I/O were evaluated. Direct I/O showed no improvement in average read latency, the metric of focus at the time, but the wrong one.Introducing Direct I/O
Direct I/O allows the application to read and write directly between disk and a userspace buffer, bypassing the page cache entirely. It requires both disk operations and off-heap memory buffers to be aligned to the filesystem block size.
Control of disk operations is transferred from the kernel to the application, eliminating writeback storms and protecting the page cache from pollution by readahead and read-once workloads.
Compaction is a prime candidate for Direct I/O on both the read and write path, with the read path addressed in this post. Input SSTables are read-once by definition; once compaction completes, that data will never be accessed again.
The output SSTable, while not throwaway, is unlikely to see much read traffic. Freshly written SSTables are typically superseded by further compaction before they see meaningful access. Neither benefits from page cache residency.
The loss of kernel readahead is mitigated by Cassandra's own chunk readahead buffer, introduced in Cassandra 5 by Jon Haddad and Jordan West. Jon Haddad, a long-time Cassandra contributor and consultant who writes on Cassandra internals at his blog, also filed the Jira to bring Direct I/O support to the compaction read path.
I picked up the work, landing in this PR targeting Cassandra 6.
Benchmarking
Environment: Ubuntu 22.04, Linux 6.8.0-106-generic, 6 GB cgroup, 3 GB heap (~3 GB page cache). RAID1 NVMe, readahead 4 KB. Classic active/inactive LRU (MGLRU disabled).
Data: Cassandra 6.0-alpha2-SNAPSHOT, 2×65 GB SSTables (chunk_length_kb=4). Major compaction with cursor compaction enabled (default), unthrottled.
Workload: 10K reads/s across a variable number of hot partitions (100K–10M, ~100 MB–10 GB). Page cache dropped and Cassandra restarted before each run.
Headline numbers
Starting with the 100 MB hot set, comfortably within the 3 GB page cache:
| Metric | Direct I/O | Buffered | Improvement |
|---|---|---|---|
| p50 | 0.31 ms | 0.42 ms | 1.4× |
| p99 | 1.33 ms | 6.88 ms | 5.2× |
| p99.9 | 11.70 ms | 15.34 ms | 1.3× |
| Mean | 0.38 ms | 0.68 ms | 1.8× |
The headline is the 5x improvement at p99, driven by cache eviction under compaction pressure. But p50 improves by 1.4x. That surprised me. Eviction doesn't explain that; a median read is a cache hit, not a disk miss.
The tail: where the win lives
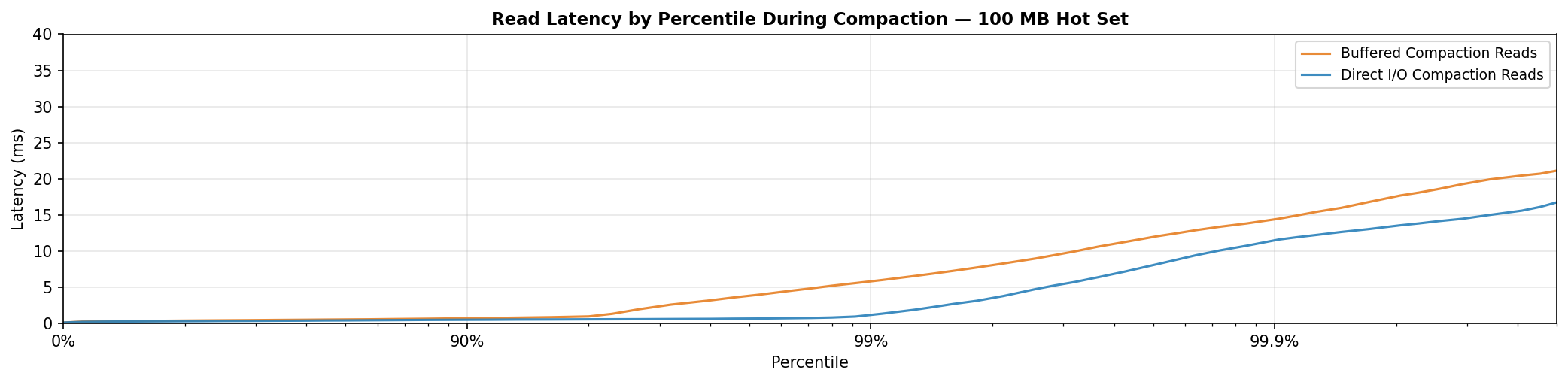
The tail is where DIO's headline win lives. Buffered climbs steeply beyond p90 to ~6 ms at p99 against ~1 ms for DIO, a 5× improvement. The gap narrows at p99.9 as other system-level bottlenecks dominate the extreme tail.
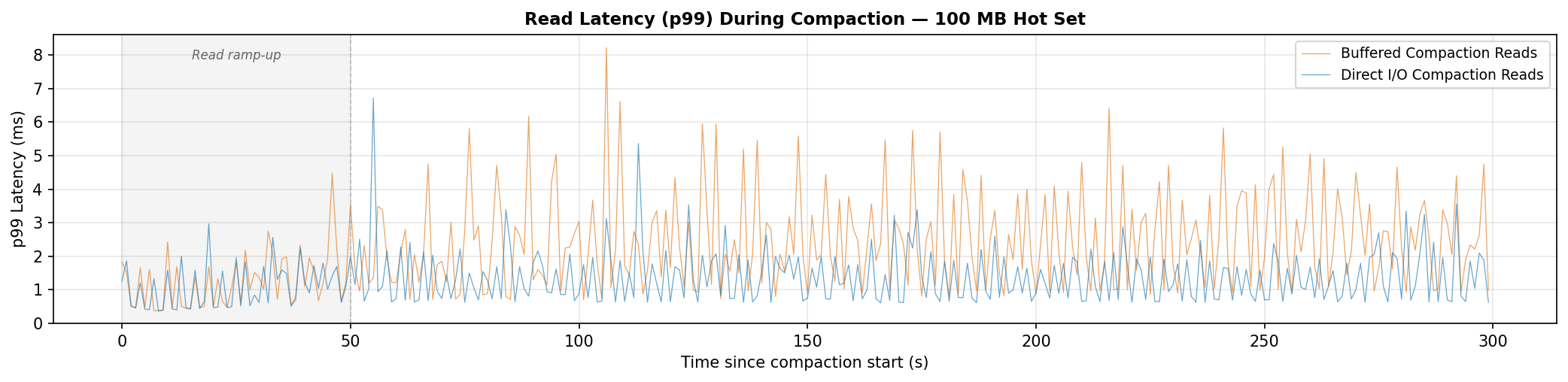
DIO (blue) mostly holds below 2 ms. Buffered (orange) frequently spikes to 4–8 ms as compaction evicts the hot dataset from the page cache, forcing read queries to hit disk. The refault data confirms it.
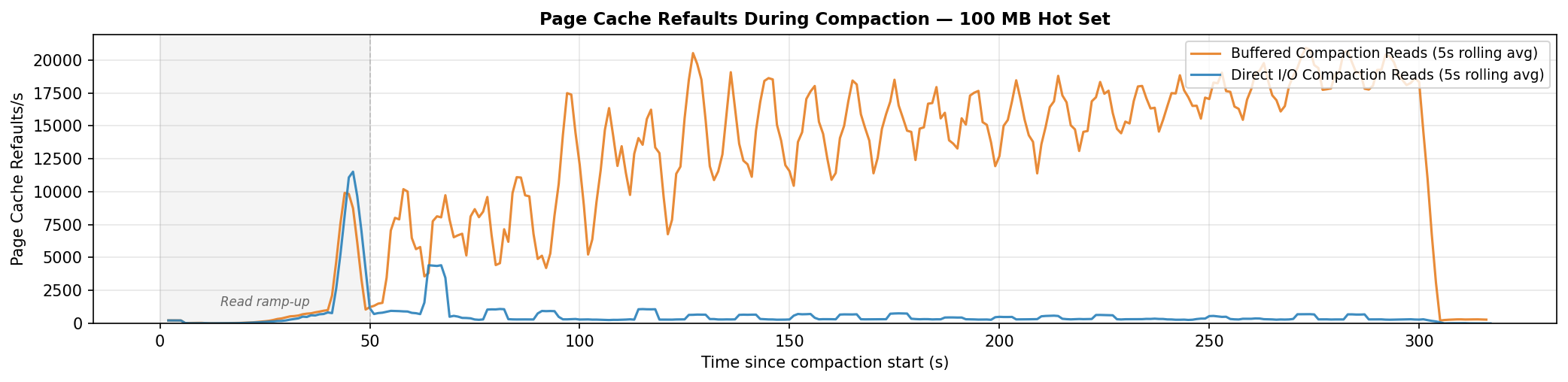
A refault is a disk read for a page that was just evicted. The cache had it, lost it under pressure, and needs it back. High refault rates mean the cache is thrashing.
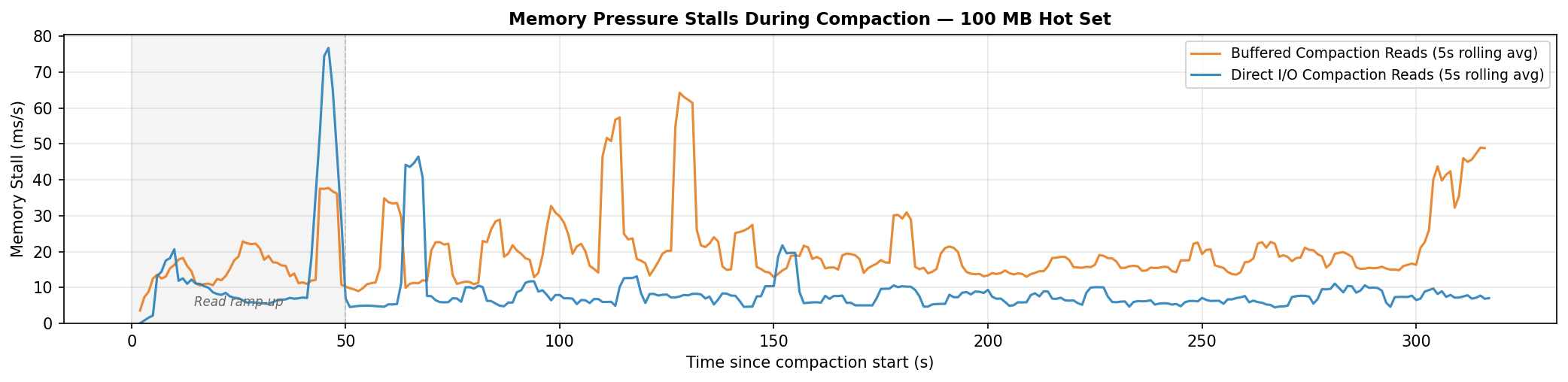
| Metric | Direct I/O | Buffered | Reduction |
|---|---|---|---|
| Mean stall | 9.5 ms/s | 20.3 ms/s | −53% |
| Total stall | 3.0 s | 6.5 s | −54% |
DIO cuts total memory stall time by 54%. Long pauses above 20ms become rare.
p99 explains itself. p50 doesn't. Buffered runs 1.4× slower at the median, but a median read is a cache hit, not a disk miss. Eviction can't be the whole story.
The median: a second mechanism
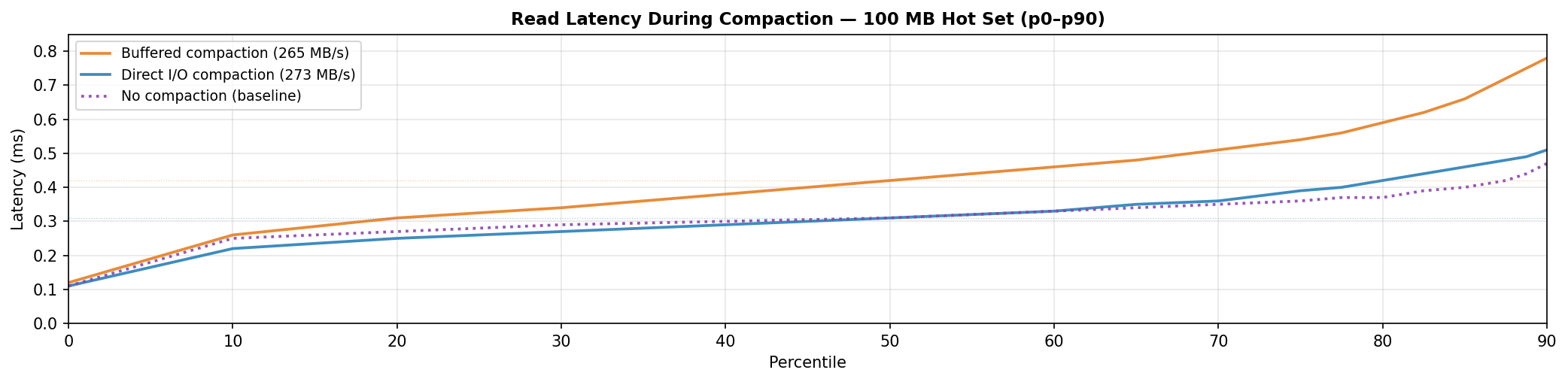
A no-compaction baseline isolates the cause. Buffered reads track DIO almost perfectly across the sub-p90 range. There is no intrinsic penalty to buffered I/O in this setup; the gap only opens when compaction is active.
The mechanism is the page cache machinery itself. At 265 MB/s, compaction drives ~66,000 pages per second through the kernel's LRU lists, with the flag updates, list manipulation, and memory copies that entails. Reader threads traversing the same machinery pay a price for the activity around them, shifting the whole distribution rightward. DIO removes compaction from the page cache path entirely; reader threads get a quiet cache.
Larger hot sets
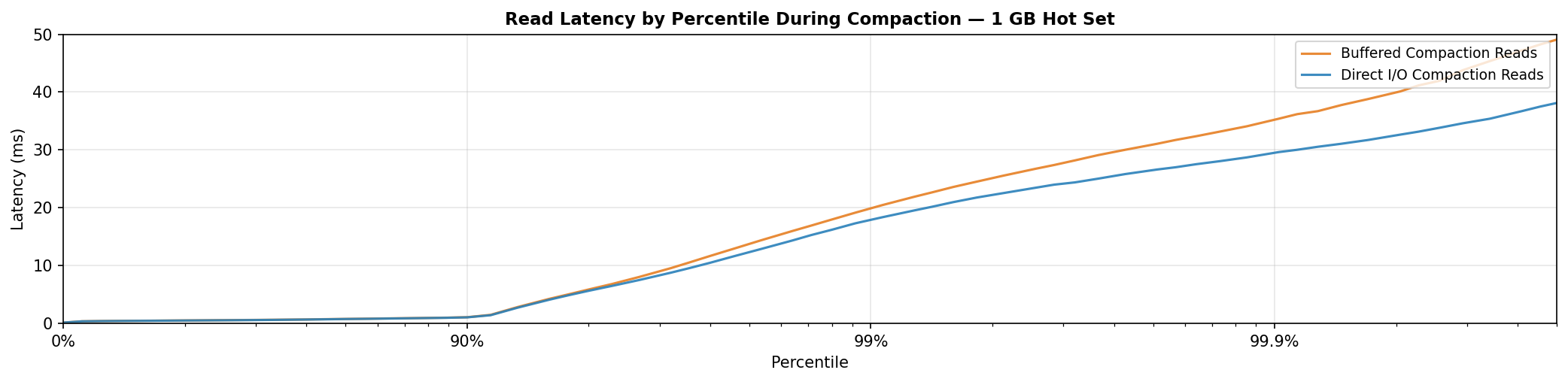
With a 1 GB hot set, both curves climb steeply from p90 onward. DIO reaches ~18 ms at p99 against ~20 ms for buffered.
At this working set size, each page is re-accessed roughly every 100 seconds. The inactive list only holds pages for ~3 seconds under buffered I/O, or ~16 seconds under DIO. Both are far short of the re-access interval, so pages are evicted before they can be promoted, and both configurations hit disk at similar rates.
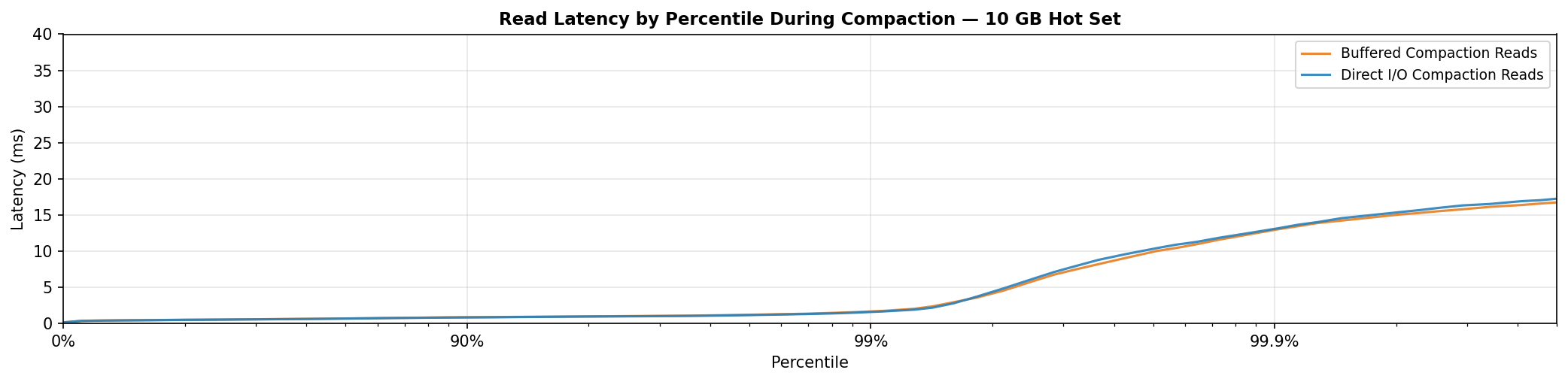
With a 10 GB hot set, larger than the entire ~3 GB page cache, the curves are effectively identical. Every read is a cache miss regardless of compaction mode; DIO has nothing to protect: it is a zero-downside change. It helps when the hot set fits in cache and is neutral when it doesn't.
Does bypassing the page cache hurt compaction throughput?
Compaction throughput
| Memory | Direct I/O | Buffered | Improvement |
|---|---|---|---|
| 12GB | 273 MiB/s | 265 MiB/s | +3% |
| 6GB | 273 MiB/s | 254 MiB/s | +7% |
DIO compaction reads are slightly faster, increasingly so as memory is constrained. Bypassing the page cache eliminates the kernel-side memory copy that buffered reads incur.
Should You Enable It?
When read queries re-access hot pages faster than compaction can evict them, DIO delivers a 5x improvement at p99 read latency and a 50% reduction in memory pressure stalls. Compaction throughput is unaffected, and marginally faster under memory constraint. As the hot set grows or compaction throughput decreases, the benefit narrows; when every read is a cache miss regardless, the curves converge and DIO costs nothing.
To enable Direct I/O for compaction reads, Cassandra v6+ is required with the following property set:
compaction_read_disk_access_mode: direct (default: auto)
Should you enable it? Yes.
Compaction input data is throwaway. Direct I/O on the read path keeps it off the page cache, extending the inactive list residence time of your hot data, improving its chances of promotion. If your working set fits in memory, you see the benefit. If it doesn't, you lose nothing.
Benchmarks were run on NVMe. On slower storage, the mechanism predicts a larger gap: evicted hot pages cost substantially more to refault. The buffered baseline gets worse; DIO doesn't. The p99 gap widens.
Future Work
Compaction reads are just the beginning. Direct I/O for compaction writes eliminates a second, larger source of cache pollution, dirty page writeback.
Buffered writes are flushed to disk by the kernel, consuming I/O bandwidth and creating memory pressure that competes with the read path. Under heavy compaction load, this can escalate into writeback storms: bursts of kernel-driven I/O that saturate disk bandwidth and cause latency spikes.
Early benchmarks suggest the gains will be substantially larger. Dirty pages are more expensive to evict than clean ones, and application-controlled flushes replace the kernel's bursty writeback with a predictable cadence.
Even with throttled compaction at 128MB/s, p99 read latency improves 5x. Write path pollution is significant even at moderate compaction rates.
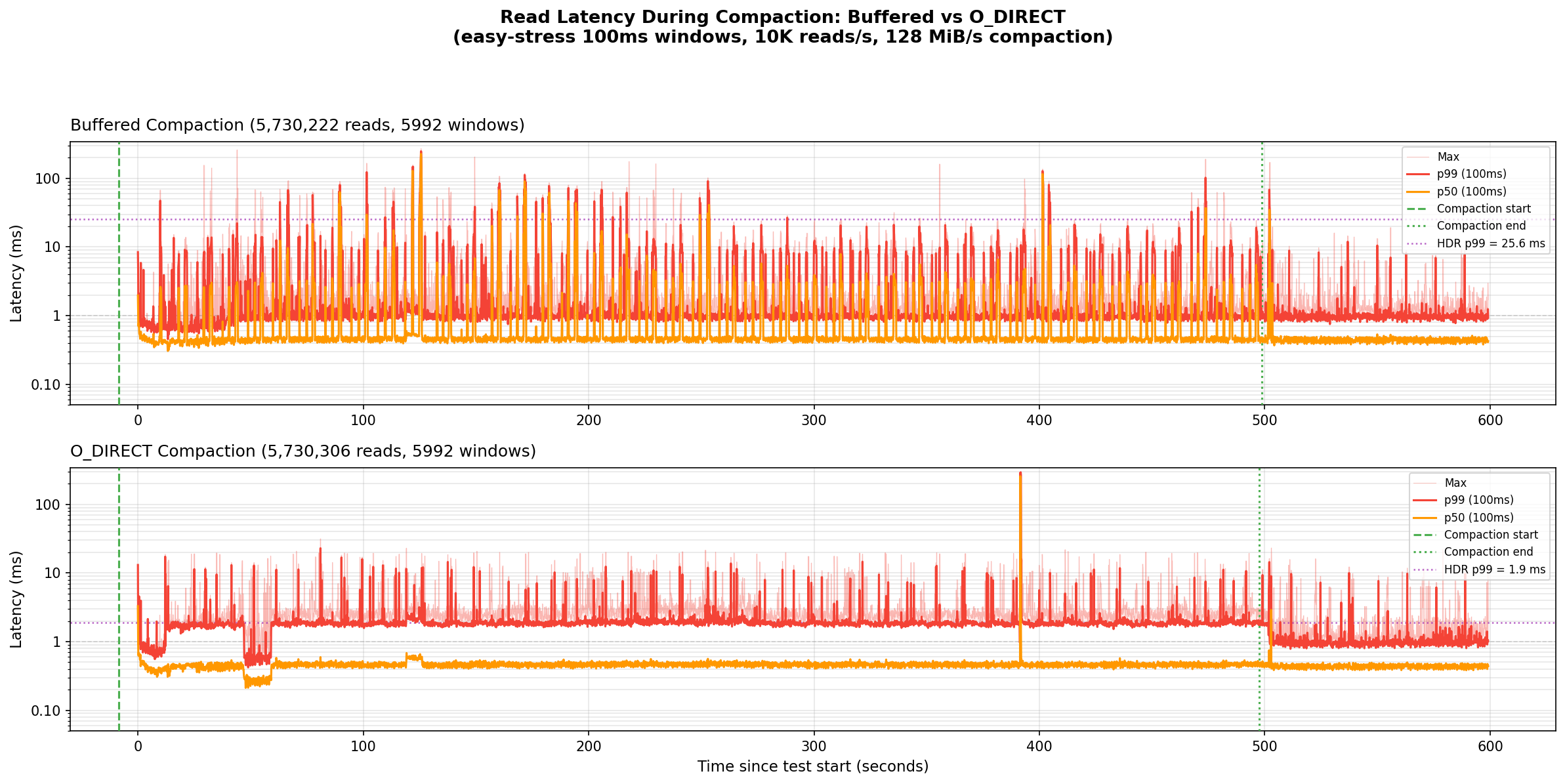
Buffered p99 (top) spikes repeatedly throughout compaction, driven by writeback storms polluting the read path. DIO (bottom) remains largely stable.
The work continues on the Jira.
Acknowledgements
Thanks to Ariel Weisberg and Maxwell Guo for their thorough code review, and to Dmitry Konstantinov for the probing DIO performance questions, all of which made both the implementation and this write-up sharper.