Why Aren't You Idempotent?

Idempotency doesn't get the attention it deserves.
It enables a distributed system to be both resilient and performant.
If, like us, you’re building low-latency APIs and face significant penalties for breaching SLAs, this article may be worth your time.
What is idempotency?
Idempotency is the quality of an action that, no matter how many times you repeat it, achieves the same outcome as doing it just once. For API endpoints, this means that if the same HTTP request is processed multiple times, the result will always be as if it were handled only once.
By way of contradiction, an example of an operation that isn’t idempotent is incrementing a counter. Each time you increment, the result (and state) changes.
What's the big deal?
In the unpredictable world of distributed systems, where noisy neighbours and unreliable networks are the norm, things are bound to go sideways. Packets drop, resources run dry and thus, latencies spike, often culminating in client-side timeouts (which, naturally, you’ve thoughtfully configured).
Whether you’re taking a proactive stance or reacting to chaos, the road to achieving those many nines of availability inevitably leads to introducing fault-tolerance measures to shield your system from the turbulence of its environment.
Retries, touted as the magic fix when things go wrong, are often the first port of call, and rightly so.
Picture this: a switch on the network route briefly experiences buffer overload, causing your response packet to be dropped, or the server handling your request sees its CPU usage spike momentarily thanks to an unruly background process (definitely worth raising a Jira for that). These are classic examples of transient errors, where a simple retry is highly likely to succeed.
But before you reach for Thor’s hammer and sprinkle retries everywhere, pause to ask the one question that matters: is it truly safe?
Safely retrying an operation has a key precondition in ensuring that no unintended side effects occur—most importantly, that no actions are applied twice. Put simply, the endpoint you’re retrying must be idempotent.
How do we build idempotent endpoints?
Designing idempotent endpoints can be challenging, so it’s important to factor it in prior to implementation. Techniques like storing external state for each request can detect prior processing, but they can also conflict with your system’s non-functional requirements—particularly when it comes to performance.
Our experience with Apache Cassandra
Apache Cassandra was our primary datastore and it provided low single-digit millisecond writes. Preserving that performance was non-negotiable, so we had to find strategies that would ensure endpoint idempotency without compromising Cassandra’s inherent speed.
Let's consider a few of the common techniques we adopted:
1. Client-supplied identifiers
Issue: IDs generated on the server-side change on each re-invocation, meaning retries can lead to multiple inserts and orphaned data.
Solution: Have the client supply the identifier. In Cassandra, this idea extends to having the client provide all the data that forms the primary key. For non-primary-key data, it usually isn’t problematic to regenerate identifiers on retry.
2. Client-supplied timestamps
Issue: endpoint call attempts that were retried are later processed, and overwrite updates that happened in-between, leading to incorrect data (from out-of-order updates).

Solution: use client-supplied timestamps on Cassandra queries.
Cassandra employs a last-write-wins model for determining which data is returned to the client, using timestamps for both reads and writes. By adopting a similar strategy as client-supplied identifiers, but this time using timestamps provided by the client, all retry attempts are made in an idempotent fashion.
In our experience, these inbound timestamps often originated from a request that has travelled through 10+ different services before arriving at our Cassandra talking data service, demonstrating the invasiveness of the client-supplied data pattern.
INSERT INTO my_keyspace.my_table (id, info)
VALUES (1, 'Some info')
USING TIMESTAMP <timestamp>;Client-supplied Cassandra query timestamp
3. Calibrated counters
This post would not be complete without mentioning counter idempotency. Cassandra has a counter data type that is thread-safe and can be incremented/decremented as you would expect.
Issue: if a timeout occurs, you have no idea if the mutation was applied (i.e. we have no idea if the request ever arrived at the Cassandra node).
Even if you track counter operations with external state for a specific identifier (often referred to as an idempotency key), if the query fails or times out, you cannot be certain whether it was applied.
Solution One: support retries and periodically calibrate the counters.
Our system was able to tolerate skewed counter values for a short period of time. This was a luxury, as it allowed us to introduce a calibration mechanism that compared the counter values against data in a different table that was not susceptible to skew. Calibration would run once per minute, which was suited to our workload.
We often observed that our counters served as a streamlined summary of data already persisted in a more detailed format. This naturally made the calibration pattern a frequently adopted approach.
Solution Two: use an idempotent data structure.
If you're unable to tolerate skewed counter values (and be truly idempotent), you'll likely need to replace the counters with a different data structure. Cassandra has the Set data type in which the add/remove operations are idempotent (when using client-supplied timestamps). You can then read the set and count the elements. This is notably heavier on Cassandra, but that's the trade-off for consistency.
It's worth mentioning Sets mutated with a large number of deletes will accumulate tombstones which will slow down reads significantly. If you do go down this route, be aware of the property gc_grace_seconds which controls how long tombstones remain on disk before being purged (and thus are not read).
A further benefit: taming the tail with hedged requests
We've seen the benefits of idempotency for resilience, but how about for latency improvements?
Per Jeff Dean in The Tail at Scale, one of the most effective ways to curb latency variability is to hedge your requests, which means to send it to many replicas. This is very similar to retrying on a timeout (or other error), except you're being more proactive and typically hedge after a delay much shorter than your configured timeout.
Hedging comes with the same precondition of idempotency as many replicas could be processing the request in parallel.
- Jeff Dean, The Tail at Scale
In our WebFlux-based system, we were able to implement request hedging in around 15 lines of code, and for our most critical flow with the most stringent latency requirements, it brought our p999 latency down from 1200ms to 450ms.
We opted to hedge in-line with our p99 latency (i.e. schedule the first hedged request after a delay equal to the endpoints p99 latency has elapsed), but if resources are no issue and latency is the goal, you can be more aggressive!
Tip: the same strategy can be applied at the query level with speculative executions, natively supported in the Cassandra DataStax client driver.
Fault-tolerance Libraries
Building fault-tolerance primitives into your system may not be something you want to spend time doing, and this is understandable given the tools available. If you are able to find a robust library that fits the performance requirements of your system, it might be the best first step.
In researching for this post, I came across references to various libraries and products that assist with durable execution, including Temporal, Azure Durable Functions, and DBOS.
DBOS, for example, provides an annotation driven API to build resilient workflows, supporting automatic resumption from any interrupted state. It has libraries for TypeScript and Python and uses Postgres as the backend state store.
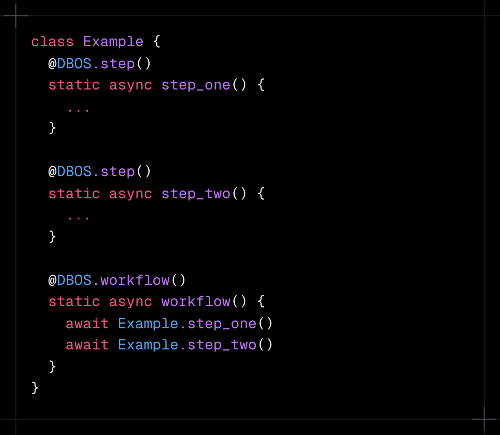
- Qian Li, DBOS on X
DBOS also published their benchmark against AWS Step Functions here, observing up to a 25x speed improvement. An exciting time for the durable execution landscape!
These libraries follow the external state management pattern, introducing some overhead to instrumented workflows due to additional persistence steps. While they simplify orchestration and resilience, the same idempotency requirements apply. They guarantee at-least-once execution, meaning you must still ensure that retries do not cause unintended side effects in your workflows.
Update: this gained some traction on Reddit, drawing some particularly interesting comments around clock synchronization.
